Vision-Speech Models: Teaching Speech Models to Converse about Images
Vision-Speech Models: Teaching Speech Models to Converse about Images
MoshiVis adapts a speech LLM (Moshi) to understand images using lightweight cross-attention modules trained on mixed image-text and image-speech data. 🎙️ Demonstrates text-to-audio knowledge transfer despite distribution shift, enabling real-time visual conversations without speech-paired training data.
My Notes
Research Gaps & Open Questions
- No comparison to Mini-Omni2 (2024) or AnyGPT (2024) on shared audio-visual benchmarks with standardized metrics—unclear how the lightweight adaptation approach compares to joint pretraining methods that also handle audio-visual inputs. Matters because computational efficiency claims need direct baseline comparisons.
- Missing evaluation on standard VLM reasoning benchmarks like TextVQA, ChartQA, or visual reasoning tasks beyond VQAv2—only tests captioning, basic VQA, and OCR. Limits understanding of whether text-to-audio transfer works for complex multi-step reasoning versus pattern recognition.
- No human evaluation of conversation quality, prosody preservation, or turn-taking naturalness compared to Moshi baseline—only automated MOSNet scores and qualitative samples in appendix. Critical gap since preserving conversational abilities is a stated core objective (challenge iii).
- Synthetic dialogue generation pipeline uses Mistral-Nemo and fixed TTS model—no analysis of how LLM or TTS choice affects data quality or downstream conversation abilities. Matters because synthetic data is the only source for multi-turn visual conversations and may introduce systematic biases.
- All experiments use a single frozen speech backbone (Moshi 7B) and vision encoder (PaliGemma)—architectural generalization untested. Matters because design choices may be specific to Moshi's joint text-audio tokenization and might not transfer to other speech LLMs.
- Maximum conversation length not reported and likely constrained by Moshi's context window—unclear how KV cache scales with prolonged visual dialogues beyond benchmark samples. Critical for real-world deployment where users may discuss images over extended interactions.
- Only English language evaluation—multilingual visual understanding and speech generation untested despite Moshi supporting multiple languages. Limits applicability to non-English scenarios where both speech quality and visual grounding may degrade.
- Data augmentation with
- Table 2 shows training with 75% speechless COCO yields better audio COCO performance (115 CIDEr) than 75% audio COCO (100 CIDEr)—contradicts the general trend that more audio improves audio evaluation, suggesting possible overfitting or interaction effects not discussed.
- Paper claims real-time inference with 7ms added latency on L4 GPU (§4.3) but only provides Mac Mini M4 Pro timing plots in Figure 6—inconsistent reporting makes latency claims difficult to verify across deployment scenarios.
Paper Summary
Problem
Vision-Language Models (VLMs) have achieved strong visual understanding, but equivalent Vision-Speech Models (VSMs) face three critical challenges: paired image-speech datasets are orders of magnitude scarcer than image-text data (limited to COCO caption transcripts), inference must maintain real-time latency for natural conversation, and models must preserve prosodic features like tone and emotion that are lost in cascaded text-transcription pipelines.
Prior speech-vision work either uses cascaded TTS systems that lose prosody and impose turn-taking, or requires expensive multi-stage joint pretraining across all modalities. The key gap is how to leverage the abundant image-text data for speech models when the speech LLM's internal text representation—containing padding tokens for temporal alignment and summed with audio embeddings—differs fundamentally in distribution from standard language modeling text.
Methodology
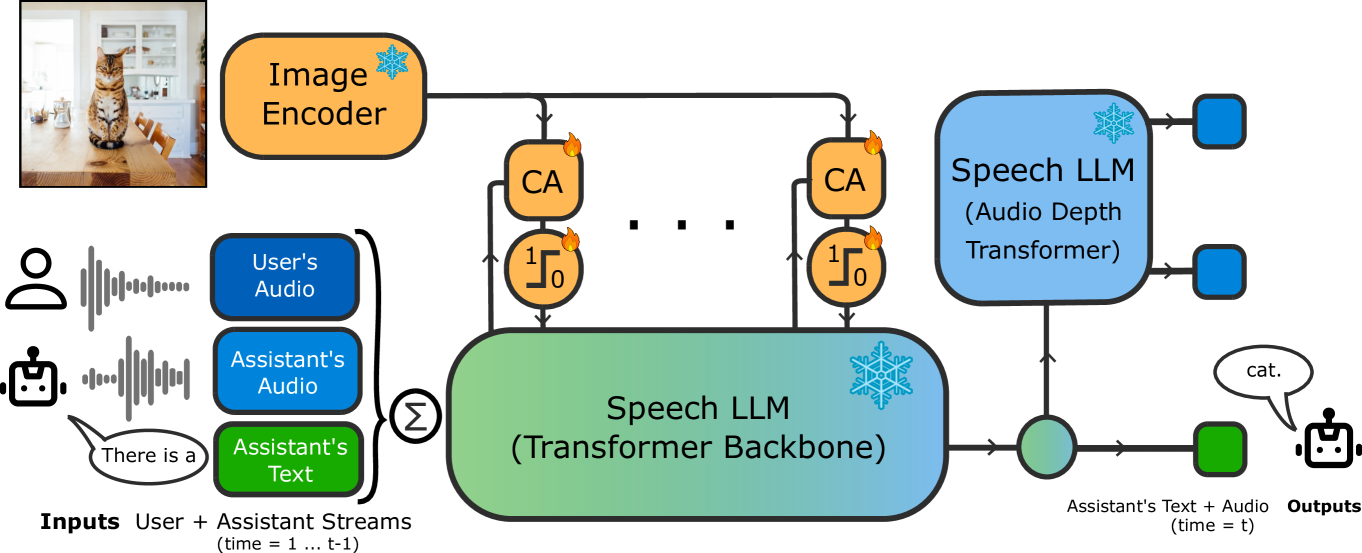
MoshiVis augments the frozen Moshi speech LLM (7B parameters) with residual cross-attention layers inserted between self-attention and feedforward blocks in every transformer layer (Figure 2). Image tokens from a frozen PaliGemma vision encoder (400M parameters) serve as keys and values; speech tokens are queries. A self-gating mechanism (2-layer MLP with 1/8 hidden reduction + sigmoid) modulates cross-attention outputs to enable context switching between image-related and general topics. Cross-attention QKV projections are shared across all layers to reduce KV cache memory cost at inference—keys and values are computed once per image.
The training pipeline uses mixed supervision with
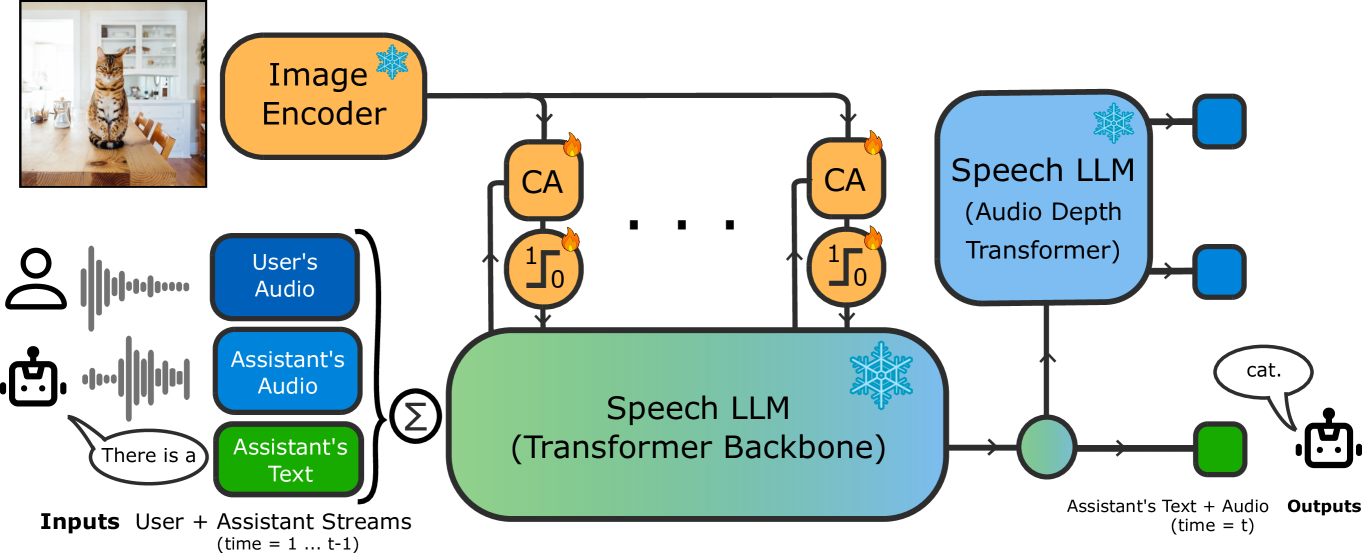
Figure 1: : MoshiVis is a Vision-Speech model ( VSM ) able to hold full-duplex real-time conversations about an image, and trained with a light data- and compute- budget.
Results
Evaluation covers three vision tasks—OCR-VQA (text recognition), VQAv2 (question answering), COCO (captioning)—in both text and audio prompt modalities. Audio datasets released for reproducibility.
With
Most surprising: text-to-audio transfer succeeds even with zero paired image-speech data during training, contradicting the assumption that modality alignment requires paired supervision. When OCR-VQA appears only as speechless data (75% of batch), audio evaluation still reaches 36.8% accuracy; adding just 10% audio boosts this to 60.7% (Tables 2-3). This indicates the joint text-audio prediction in Moshi's architecture enables cross-modal knowledge flow despite distribution mismatch.
| Method | OCR-VQA (audio) | VQAv2 (audio) | COCO CIDEr (audio) | MOSNet |
|---|---|---|---|---|
| MoshiVis (25% audio) | — | — | 113 | — |
| MoshiVis (0% audio) | 38.5 | 49.3 | 113 | 2.78 |
| MoshiVis (1% audio) | — | — | — | 3.59 |
| Moshi (baseline) | — | — | — | 3.34 |
| PaliGemma stage-3 | — | — | — | — |

Table 5: : Examples of generated COCO captions for a conversational MoshiVis ( top rows ) and a MoshiVis directly trained for COCO captioning as a downstream task ( bottom rows ). While both models yield quali
Ablation
Ablations examine gating mechanism and parameter sharing on OCR-VQA and COCO (§4.1, Table 4); context switching robustness with varying
Architecture ablations: No gating (66.1% OCR text eval), per-layer gates (67.7% with KV sharing, 68.2% with QKV sharing), shared gates (67.5% KV, 66.1% QKV). Performance differences within 2.1 percentage points. Context switch ablations: Without gating and
Gating mechanism has the largest impact on context switching rather than downstream accuracy. Authors claim gates implicitly learn image relevance scores; Figure 5 shows gating preserves 90-95% of base performance vs 85% without gating when switching from visual to non-visual context. Numbers confirm this claim—gating provides consistent robustness gains across prefix lengths, especially combined with
Related Work
| Paper | Authors | Year | arXiv | Connection to Gaps |
|---|---|---|---|---|
| PaliGemma: A versatile 3B VLM for transfer | Beyer et al. | 2024 | 2407.07726 | Serves as the frozen vision encoder backbone; direct comparison to stage-3 PaliGemma would clarify the cost of keeping the image encoder frozen versus fine-tuning it for downstream tasks. |
| Moshi: a speech-text foundation model for real-time dialogue | Défossez et al. | 2024 | 2410.00037 | The frozen speech LLM backbone; human evaluation comparing conversation quality to baseline Moshi would validate whether visual adaptation preserves prosodic features and turn-taking naturalness. |
| Mini-Omni2: Towards Open-source GPT-4o with Vision, Speech and Duplex Capabilities | Xie et al. | 2024 | 2410.11190 | Joint pretraining approach for audio-visual-text models; direct benchmark comparison would quantify efficiency gains of lightweight adaptation versus multi-stage joint training. |
| AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling | Zhan et al. | 2024 | 2402.12226 | Alternative approach using discrete tokens for all modalities including audio; comparison would clarify trade-offs between unified tokenization and modality-specific encoders for speech quality. |
| Visual Dialogue | Das et al. | 2017 | 1611.08669 | Foundational text-based visual dialogue dataset; extending their evaluation protocol to multi-turn audio dialogues would enable standardized measurement of conversational visual understanding beyond single QA pairs. |
BibTeX
@misc{royer2025visionspeech,
title = {Vision-Speech Models: Teaching Speech Models to Converse about Images},
author = {Royer, Amélie and Böhle, Moritz and Marmiesse, Gabriel de and Mazaré, Laurent and Zeghidour, Neil and Défossez, Alexandre and Pérez, Patrick},
year = {2025},
eprint = {2503.15633},
archivePrefix = {arXiv},
primaryClass = {cs.CV},
url = {https://arxiv.org/abs/2503.15633}
}