📄
Publications
2026

2025

2024

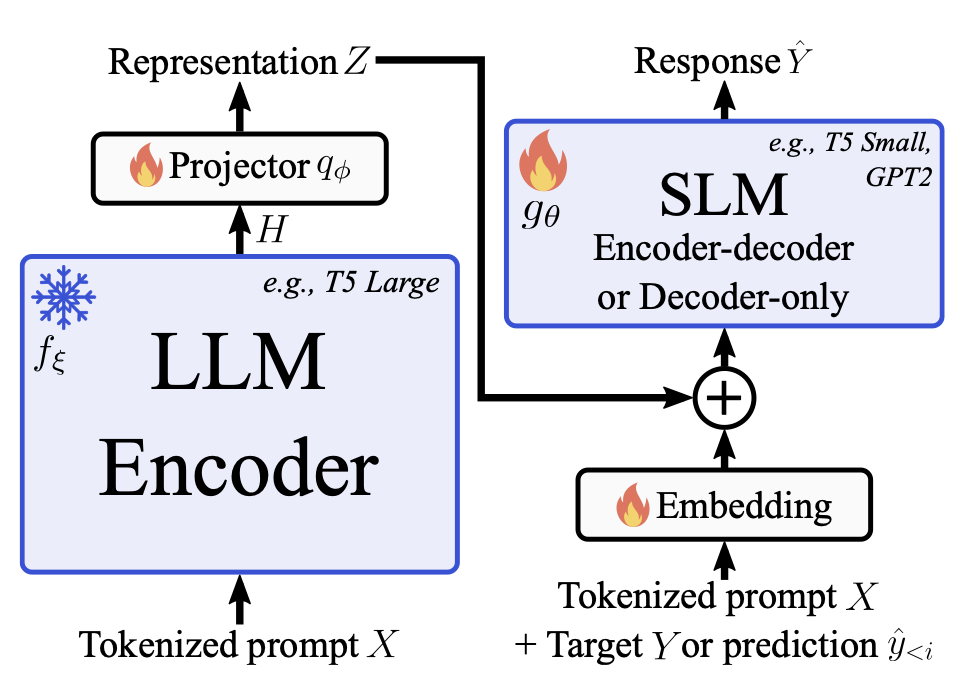
Think Big, Generate Quick: LLM-to-SLM for Fast Autoregressive Decoding
Benjamin Bergner, Andrii Skliar, , Tijmen Blankevoort, Yuki Asano, Babak Ehteshami Bejnordi
ES-FoMo II Workshop, ICML 2024
2023

2022
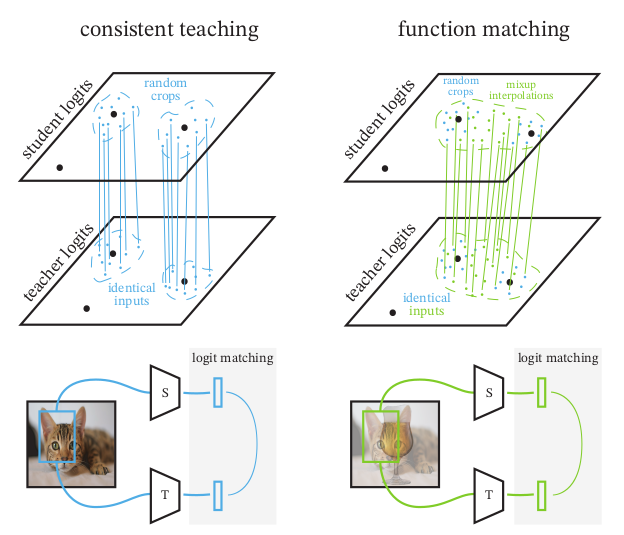
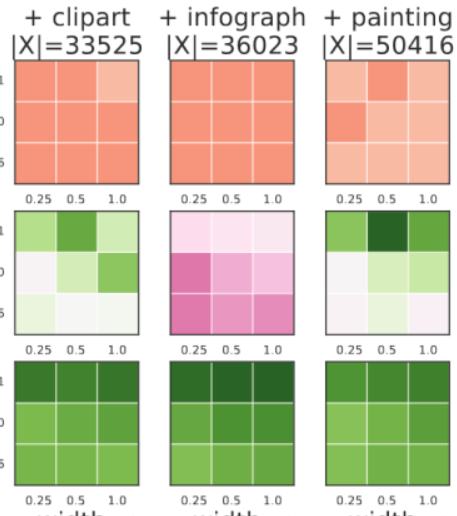
Knowledge Distillation: A good teacher is patient and consistent
Lucas Beyer*, Xiaohua Zhai*, *, Larisa Markeeva*, Rohan Anil, Alexander Kolesnikov
Conference on Computer Vision and Pattern Recognition (CVPR) (oral) 2022