
A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Pages
Page Not Found
Welcome
Archive Layout with Content
Posts by Category
Posts by Collection
Resume
Markdown
Page not in menu
Page Archive
Portfolio
Publications
Sitemap
Posts by Tags
Talk map
Terms and Privacy Policy
Blog posts
, in
Posts
A Style-Based Generator Architecture for Generative Adversarial Networks
Karras et al., in CVPR 2019In this work, the authors propose VQ-VAE, a variant of the Variational Autoencoder (VAE) framework with a discrete latent space, using ideas from vector quantization. The two main motivations are (i) discrete variables are potentially better fit to capture the structure of data such as text and (ii) to prevent the posterior collapse in VAEs that leads to latent variables being ignored when the decoder is too powerful.
Domain Adversarial Training of Neural Networks
Ganin et al., in JMLR 2016In this article, the authors tackle the problem of unsupervised domain adaptation: Given labeled samples from a source distribution `\mathcal D_S` and unlabeled samples from target distribution `\mathcal D_T`, the goal is to learn a function that solves the task for both the source and target domains. In particular, the proposed model is trained on both source and target data jointly, and aims to directly learn an aligned representation of the domains, while retaining meaningful information with respect to the source labels.
Deep Image Prior
Ulyanov et al., in CVPR 2018Deep Neural Networks are widely used in image generation tasks for capturing a general prior on natural images from a large set of observations. However, this paper shows that the structure of the network itself is able to capture a good prior, at least for local cues of image statistics. More precisely, a randomly initialized convolutional neural network can be a good handcrafted prior for low-level tasks such as denoising, inpainting.
Learning a SAT Solver from Single-Bit Supervision
Selsam et al., in ICLR 2019The goal is to solve SAT problems with weak supervision: In that case, a model is trained only to predict the satisfiability of a formula in conjunctive normal form. As a byproduct, if the formula is satisfiable, an actual satisfying assignment can be worked out from the network's activations in most cases.
Automatically Composing Representation Transformations as a Mean for Generalization
Chang et al., in ICLR 2019The authors focus on solving recursive tasks which can be decomposed into a sequence of simpler algorithmic procedures (e.g., arithmetic problems, geometric transformations). The main difficulties of this approach are (i) how to actually decompose the task into simpler blocks and (ii) how to extrapolate to more complex problems from learning on simpler individual tasks. The authors propose the compositional recursive learner (CRL) to learn at the same time both the structure of the task and its components.
A simple Neural Network Module for Relational Reasoning
Santoro et al., in NeurIPS 2017The authors propose a relation module to equip CNN architectures with notion of relational reasoning, particularly useful for tasks such as visual question answering, dynamics understanding etc.
Glow: Generative Flow with Invertible 1×1 Convolutions
D. Kingma and P. Dhariwal, in NeurIPS 2018Invertible flow based generative models such as [2, 3] have several advantages including exact likelihood inference process (unlike VAEs or GANs) and easily parallelizable training and inference (unlike the sequential generative process in auto-regressive models). This paper proposes a new, more flexible, form of invertible flow for generative models, which builds on [3].
The Reversible Residual Network: Backpropagation Without Storing Activations
Gomez et al., in NeurIPS 2017Residual Networks (ResNet) [3] have greatly advanced the state-of-the-art in Deep Learning by making it possible to train much deeper networks via the addition of skip connections. However, in order to compute gradients during the backpropagation pass, all the units' activations have to be stored during the feed-forward pass, leading to high memory requirements for these very deep networks. Instead, the authors propose a reversible architecture in which activations at one layer can be computed from the ones of the next. Leveraging this invertibility property, they design a more efficient implementation of backpropagation, effectively trading compute power for memory storage.
Conditional Neural Processes
Garnelo et al., in ICML 2018Gaussian Processes are models that consider a family of functions (typically under a Gaussian distribution) and aim to quickly fit one of these functions at test time based on some observations. In that sense there are orthogonal to Neural Networks which instead aim to learn one function based on a large training set and hoping it generalizes well on any new unseen test input. This work is an attempt at bridging both approaches.
The Neuro-Symbolic Concept Learner
Mao et al., in ICLR 2019Here the authors tackle the problem of Visual Question Answering. They propose to learn jointly from visual representations and text-level knowledge (question-answer pairs). They further make use of (i) curriculum learning and (ii) a differentiable symbolic solver for reasoning.
Deep Visual Analogy Making
Reed et al., in NeurIPS 2015In this paper, the authors propose to learn visual analogies akin to the semantic and synctatic analogies naturally emerging in the Word2Vec embedding [1]: More specifically hey tackle the joint task of inferring a transformation from a given (source, target) pair, and applying the same relation to a new source image.
Do Deep Generative Models Know what they don’t Know ?
Nalisnick et al., in ICLR 2019CNNs' prediction landscapes are known to be very sensitive to adversarial examples, which are small perturbations of an image, indistinguishable to the human eye, that lead to wrong predictions with high confidence. On the other hand, probabilistic generative models such as PixelCNNs and VAEs are trained to model a distribution over the input images, thus could be used to detect out-of-distribution inputs by estimating their likelihood under the data distribution. This paper provides interesting results showing that distributions learned by generative models are not robust enough yet for such purposes.
Excessive Invariance Causes Adversarial Vulnerability
Jacobsen et al., in ICLR 2019The authors introduce the notion of invariance-based adversarial examples, which can be seen as a generalization of adversarial examples at the feature level: Given an image `x` and a pretrained classifier, it is possible to generate an image that is both semantically plausible and distinct from `x`, and yet yields the exact same output logits under the classifier. The authors study this scenario in the context of invertible networks, e.g., i-RevNet [1].
The Variational Fair Autoencoder
Louizos et al., in ICLR 2016The goal of this work is to propose a variational autoencoder based model that learns latent representations which are independent from some sensitive knowledge present in the data, while retaining enough information to solve the task at hand, e.g. classification. This independence constraint is incorporated via loss term based on Maximum Mean Discrepancy.
InfoVAE: Balancing Learning and Inference in Variational Autoencoders
Zhao et al., in AAAI 2019Two known shortcomings of VAEs are that (i) The variational bound (ELBO) can lead to poor approximation of the true likelihood and inaccurate models and (ii) the model can ignore the learned latent representation when the decoder is too powerful. In this work, the author propose to tackle these problems by adding an explicit mutual information term to the standard VAE objective.
Domain Generalization with Adversarial Feature Learning
Li et al., in CVPR 2018In this paper, the authors tackle the problem of Domain Generalization: Given multiple source domains, the goal is to learn a joint aligned feature representation, hoping it would generalize to a new unseen target domain. This is closely related to the Domain Adaptation task, with the difference that no target data (even unlabeled) is available at training time. Most approaches rely on the idea of aligning the source domains distributions in a shared space. In this work, the authors propose to additionally match the source distributions to a known prior distribution.
Neural Discrete Representation Learning
Van den Oord et al., in NeurIPS 2017In this work, the authors propose VQ-VAE, a variant of the Variational Autoencoder (VAE) framework with a discrete latent space, using ideas from vector quantization. The two main motivations are (i) discrete variables are potentially better fit to capture the structure of data such as text and (ii) to prevent the posterior collapse in VAEs that leads to latent variables being ignored when the decoder is too powerful.
From Red Wine to Red Tomato: Composition with Context
Misra et al., in CVPR 2017In this paper, the authors tackle the problem of learning classifiers of visual concepts that can also adapt to new concept compositions at test time. The main difficulty is that visual concept can different depending on the context, i.e., depending on the concepts they are combined with. For instance the red in "red tomato" is different from the one in "red wine". This work emphasizes the notion of visual concepts as composition units, rather than the usual paradigm of directly learning from large exhaustive datasets.
Gradient Reversal Against Discrimination
E. Raff and J. Sylvester, in DSAA 2018In this work, the authors tackle the problem of learning fair representations, i.e. representations that should be insensitive to some given sensitive attribute, while retaining enough information to solve the task at hand. Given some input data `x` and attribute `a_p`, the task is to predict label `y` from `x` while making the attribute `a_p` protected, in other words, such that predictions are invariant to changes in `a_p`.
Measuring Abstract Reasoning in Neural Networks
Barrett et al., in ICML 2018The authors introduce a new visual analogy dataset with the aim to analyze the reasoning abilities of ConvNets on higher abstract reasoning tasks such as small IQ tests.
LaSO: Label-Set Operations Networks for Multi-label Few-Shot Learning
Alfassy et al., in CVPR 2019In this paper, the authors tackle the problem of "multi-label few-shot learning", in which a multi-label classifier is trained with few samples of each object category, and is applied on images that contain potentially new combinations of the categories of interest. The key idea of the paper is to synthesize new samples at the feature-level by mirroring set operations (union, intersection, subtraction), hoping to the train/test distribution shift and improve the model's generalization abilities.
portfolio
Grabplot: Interactive Plotting with matplotlib
Variational Auto-encoders
Generative Latent Optimization
Wonderwheel
Mesh Generation with Alpha Complexes
VQ-VAE
The Pólya Urn
Deep Image Prior
GLOW: Generative flow
Codenames Solo
publications

Classifier Adaptation at Prediction Time
in Conference on Computer Vision and Pattern Recognition (CVPR), 2015
Classifiers for object categorization are usually evaluated by their accuracy on a set of i.i.d. test examples. This provides us with an estimate of the expected error when applying the classifiers to a single new image. In real application, however, classifiers are rarely only used for a single image and then discarded. Instead, they are applied sequentially to many images, and these are typically not i.i.d. samples from a fixed data distribution, but they carry dependencies and their class distribution varies over time.
In this work, we argue that the phenomenon of correlated data at prediction time is not a nuisance, but a blessing in disguise. We describe a probabilistic method for adapting classifiers at prediction time without having to retraining them. We also introduce a framework for creating realistically distributed image sequences, which offers a way to benchmark classifier adaptation methods, such as the one we propose.
Experiments on the ILSVRC2010 and ILSVRC2012 datasets show that adapting object classification systems at prediction time can significantly reduce their error rate, even with additional human feedback.
author = {Royer, Am\'{e}lie and Lampert, Christoph H.},
title = {Classifier Adaptation at Prediction Time},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2015}
}

Audio Word Similarity for Clustering with zero Resources based on iterative HMM Classification
in International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2016
Recent work on zero resource word discovery makes intensive use of audio fragment clustering to find repeating speech patterns. In the absence of acoustic models, the clustering step traditionally relies on dynamic time warping (DTW) to compare two samples and thus suffers from the known limitations of this technique.
We propose a new sample comparison method, called ‘similarity by iterative classification’, that exploits the modeling capacities of hidden Markov models (HMM) with no supervision. The core idea relies on the use of HMMs trained on randomly labeled data and exploits the fact that similar samples are more likely to be classified together by a large number of random classifiers than dissimilar ones.
The resulting similarity measure is compared to DTW on two tasks, namely nearest neighbor retrieval and clustering, showing that the generalization capabilities of probabilistic machine learning significantly benefit to audio word comparison and overcome many of the limitations of DTW-based comparison.
author = {Royer, Am\'{e}lie, Gravier, Guillaume and Claveau, Vincent},
title = {Audio word similarity for clustering with zero resources based on iterative HMM classification},
booktitle = {International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
month = {March},
year = {2016}
}

Probabilistic Image Colorization
in British Machine Vision Conference (BMVC), 2017
We develop a probabilistic technique for colorizing grayscale natural images. In light of the intrinsic uncertainty of this task, the proposed probabilistic framework has numerous desirable properties. In particular, our model is able to produce multiple plausible and vivid colorizations for a given grayscale image and is one of the first colorization models to provide a proper stochastic sampling scheme.
Moreover, our training procedure is supported by a rigorous theoretical framework that does not require any ad hoc heuristics and allows for efficient modeling and learning of the joint pixel color distribution. We demonstrate strong quantitative and qualitative experimental results on the CIFAR-10 dataset and the challenging ILSVRC 2012 dataset.
author = {Royer, Am\'{e}lie, Kolesnikov, Alexander and Lampert, Christoph H.},
title = {Probabilistic Image Colorization},
booktitle = {British Machine Vision Conference (BMVC)},
year = {2017}
}

XGAN: Unsupervised Image-to-Image Translation for Many-to-Many Mappings
in Domain Adaptation for Visual Understanding Workshop at ICML/IJCAI/EJCAI 2018, 2018
Style transfer usually refers to the task of applying color and texture information from a specific style image to a given content image while preserving the structure of the latter. Here we tackle the more generic problem of semantic style transfer: given two unpaired collections of images, we aim to learn a mapping between the corpus-level style of each collection, while preserving semantic content shared across the two domains.
We introduce XGAN (“Cross-GAN”), a dual adversarial autoencoder, which captures a shared representation of the common domain semantic content in an unsupervised way, while jointly learning the domain-to-domain image translations in both directions. We exploit ideas from the domain adaptation literature and define a semantic consistency loss which encourages the model to preserve semantics in the learned embedding space. We report promising qualitative results for the task of face-to-cartoon translation. The cartoon dataset we collected for this purpose, CartoonSet, is publicly availale at https://google.github.io/cartoonset/index.html as a new benchmark for semantic style transfer.
author = {Am\'{e}lie Royer and Konstantinos Bousmalis and Stephan Gouws and
Fred Bertsch and Inbar Mosseri and Forrester Cole and Kevin Murphy},
title = {{XGAN:} Unsupervised Image-to-Image Translation for many-to-many Mappings},
journal = {Domain Adaptation for Visual Understanding Workshop at ICML'18},
year = {2018}
}

A Flexible Selection Scheme for Minimum-Effort Transfer Learning
in Winter Conference on Applications of Computer Vision (WACV), 2020
Fine-tuning is a popular way of exploiting knowledge contained in a pre-trained convolutional network for a new visual recognition task. However, the orthogonal setting of transferring knowledge from a pretrained network to a vi- sually different yet semantically close source is rarely considered: This commonly happens with real-life data, which is not necessarily as clean as the training source (noise, geometric transformations, different modalities, etc.).
To tackle such scenarios, we introduce a new, generalized form of fine-tuning, called flex-tuning, in which any individual unit (e.g. layer) of a network can be tuned, and the most promising one is chosen automatically. In order to make the method appealing for practical use, we propose two lightweight and faster selection procedures that prove to be good approximations in practice. We study these selection criteria empirically across a variety of domain shifts and data scarcity scenarios, and show that fine-tuning individual units, despite its simplicity, yields very good results as an adaptation technique. As it turns out, in contrast to common practice, rather than the last fully-connected unit it is best to tune an intermediate or early one in many domain shift scenarios, which is accurately detected by flex-tuning.
author = {Royer, Am\'{e}lie and Lampert, Christoph H.},
title = {A Flexible Selection Scheme for Minimum-Effort Transfer Learning},
booktitle = {Winter Conference on Applications of Computer Vision (WACV)},
year = {2020}
}
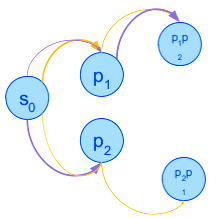
Multiple-Environment Markov Decision Processes: Efficient Analysis and Applications
in International Conference on Automated Planning and Scheduling (ICAPS), 2020
Multiple-environment Markov decision processes (MEMDPs) are MDPs equipped with not one, but multiple probabilistic transition functions, which represent the various possible unknown environments. While the previous research on MEMDPs focused on theoretical properties for long-run average payoff, we study them with discounted-sum payoff and focus on their practical advantages and applications. MEMDPs can be viewed as a special case of Partially observable and Mixed observability MDPs: the state of the system is perfectly observable, but not the environment.
We show that the specific structure of MEMDPs allows for more efficient algorithmic analysis, in particular for faster belief updates. We demonstrate the applicability of MEMDPs in several domains. In particular, we formalize the sequential decision-making approach to contextual recommendation systems as MEMDPs and substantially improve over the previous MDP approach.
author = {Royer, Am\'{e}lie and Lampert, Christoph H.},
title = {Classifier Adaptation at Prediction Time},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2015}
}

Localizing Grouped Instances for Efficient Detection in Low-Resource Scenarios
in Winter Conference on Applications of Computer Vision (WACV), 2020
State-of-the-art detection systems are generally evaluated on their ability to exhaustively retrieve objects densely distributed in the image, across a wide variety of appearances and semantic categories. Orthogonal to this, many real-life object detection applications, for example in remote sensing, instead require dealing with large images that contain only a few small objects of a single class, scattered heterogeneously across the space. In addition, they are often subject to strict computational constraints, such as limited battery capacity and computing power.
To tackle these more practical scenarios, we propose a novel flexible detection scheme that efficiently adapts to variable object sizes and densities: We rely on a sequence of detection stages, each of which has the ability to predict groups of objects as well as individuals. Similar to a detection cascade, this multi-stage architecture spares computational effort by discarding large irrelevant regions of the image early during the detection process. The ability to group objects provides further computational and memory savings, as it allows working with lower image resolutions in early stages, where groups are more easily detected than individuals, as they are more salient. We report experimental results on two aerial image datasets, and show that the proposed method is as accurate yet computationally more efficient than standard single-shot detectors, consistently across three different backbone architectures.
author = {Royer, Am\'{e}lie and Lampert, Christoph H.},
title = {Localizing Grouped Instances for Efficient Detection in Low-Resource Scenarios},
booktitle = {Winter Conference on Applications of Computer Vision (WACV)},
year = {2020}
}
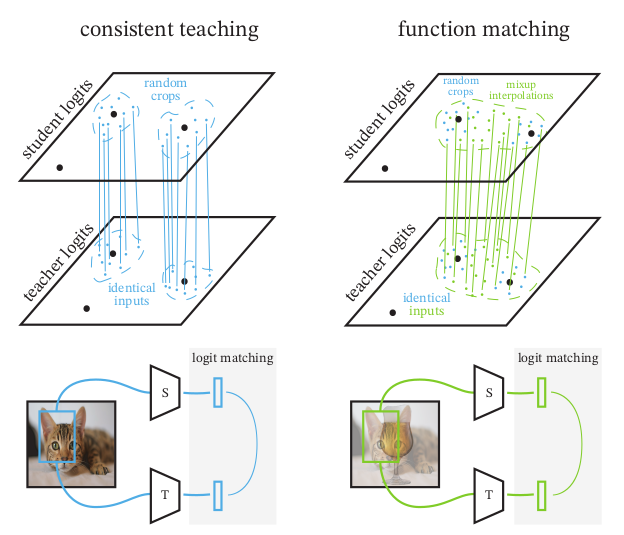
Knowledge Distillation: A good teacher is patient and consistent
in Conference on Computer Vision and Pattern Recognition (CVPR) (oral), 2022
There is a growing discrepancy in computer vision between large-scale models that achieve state-of-the-art performance and models that are affordable in practical applications. In this paper we address this issue and significantly bridge the gap between these two types of models. Throughout our empirical investigation we do not aim to necessarily propose a new method, but strive to identify a robust and effective recipe for making state-of-the-art large scale models affordable in practice. We demonstrate that, when performed correctly, knowledge distillation can be a powerful tool for reducing the size of large models without compromising their performance. In particular, we uncover that there are certain implicit design choices, which may drastically affect the effectiveness of distillation. Our key contribution is the explicit identification of these design choices, which were not previously articulated in the literature. We back up our findings by a comprehensive empirical study, demonstrate compelling results on a wide range of vision datasets and, in particular, obtain a state-of-the-art ResNet-50 model for ImageNet, which achieves 82.8% top-1 accuracy.
author = {Beyer, Lucas and Zhai, Xiaohua and Royer, Am\'elie and Markeeva, Larisa and Anil, Rohan and Kolesnikov, Alexander},
title = {Knowledge Distillation: A Good Teacher Is Patient and Consistent},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2022}
}
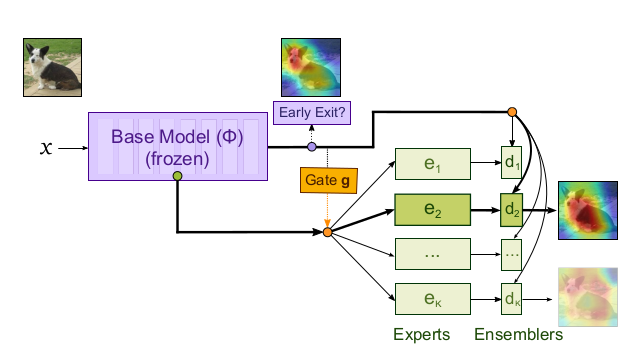
Revisiting single-gated Mixtures of Experts
in British Machine Vision Conference (BMVC), 2022
Mixture of Experts (MoE) are rising in popularity as a means to train extremely large-scale models, yet allowing for a reasonable computational cost at inference time. Recent state-of-the-art approaches usually assume a large number of experts, and require training all experts jointly, which often lead to training instabilities such as the router collapsing In contrast, in this work, we propose to revisit the simple single-gate MoE, which allows for more practical training. Key to our work are (i) a base model branch acting both as an early-exit and an ensembling regularization scheme, (ii) a simple and efficient asynchronous training pipeline without router collapse issues, and finally (iii) a per-sample clustering-based initialization. We show experimentally that the proposed model obtains efficiency-to-accuracy trade-offs comparable with other more complex MoE, and outperforms non-mixture baselines. This showcases the merits of even a simple single-gate MoE, and motivates further exploration in this area.
author = {Royer, Am\'elie and Karmanov, Ilia and Skliar, Andrii and Ehteshami Bejnordi, Babak and Blankevoort, Tijmen},
title = {Knowledge Distillation: A Good Teacher Is Patient and Consistent},
booktitle = {British Machine Vision Conference (BMVC)},
year = {2022}
}

MSViT: Dynamic Mixed-Scale Tokenization for Vision Transformers
in ICCV Workshop on New Ideas in Vision Transformers (NViT), 2023
The input tokens to Vision Transformers carry little semantic meaning as they are defined as regular equal-sized patches of the input image, regardless of its content. However, processing uniform background areas of an image should not necessitate as much compute as dense, cluttered areas. To address this issue, we propose a dynamic mixed-scale tokenization scheme for ViT, MSViT. Our method introduces a conditional gating mechanism that selects the optimal token scale for every image region, such that the number of tokens is dynamically determined per input. In addition, to enhance the conditional behavior of the gate during training, we introduce a novel generalization of the batch-shaping loss. We show that our gating module is able to learn meaningful semantics despite operating locally at the coarse patch-level. The proposed gating module is lightweight, agnostic to the choice of transformer backbone, and trained within a few epochs with little training overhead. Furthermore, in contrast to token pruning, MSViT does not lose information about the input, thus can be readily applied for dense tasks. We validate MSViT on the tasks of classification and segmentation where it leads to improved accuracy-complexity trade-off.
author = {Havtorn, Jakob and Royer, Am\'elie and Blankevoort, Tijmen and Ehteshami Bejnordi, Babak},
title = {MSViT: Dynamic Mixed-Scale Tokenization for Vision Transformers},
booktitle = {ICCV Workshop on New Ideas in Vision Transformers (NViT)},
year = {2023}
}
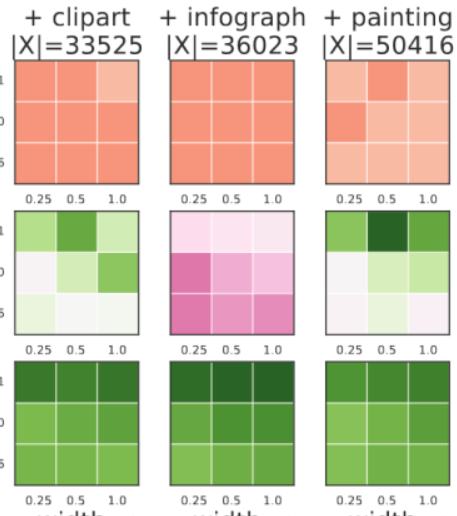
Scalarization for Multi-Task and Multi-Domain Learning at Scale
in Conference on Neural Information Processing Systems (NeurIPS), 2023
Training a single model on multiple input domains and/or output tasks allows for compressing information from multiple sources into a unified backbone hence improves model efficiency. It also enables potential positive knowledge transfer across tasks/domains, leading to improved accuracy and data-efficient training. However, optimizing such networks is a challenge, in particular due to discrepancies between the different tasks or domains: Despite several hypotheses and solutions proposed over the years, recent work has shown that uniform scalarization training, i.e., simply minimizing the average of the task losses, yields on-par performance with more costly SotA optimization methods. This raises the issue of how well we understand the training dynamics of multi-task and multi-domain networks. In this work, we first devise a large-scale unified analysis of multi-domain and multi-task learning to better understand the dynamics of scalarization across varied task/domain combinations and model sizes. Following these insights, we then propose to leverage population-based training to efficiently search for the optimal scalarization weights when dealing with a large number of tasks or domains.
author = {Royer, Am\'elie and Blankevoort, Tijmen and Ehteshami Bejnordi, Babak},
title = {Knowledge Distillation: A Good Teacher Is Patient and Consistent},
booktitle = {Conference on Neural Information Processing Systems (NeurIPS)},
year = {2023}
}