Reading Notes
The Neuro-Symbolic Concept Learner
Mao et al., ICLR 2019, [link]
tags: visual reasoning - 2019 - iclr
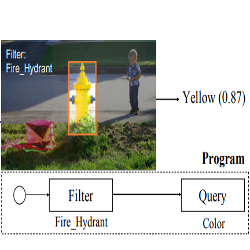
- Pros (+): They propose to model question answering as explicit programs that act on symbolic tokens, but without making use of explicit symbolic supervision, but rather use indirect supervision from visual-text grounding..
- Cons (-): A lot of components seem rather involved and/or their impact is not clear (e.g., curriculum learning, pre-trained
RCNNetc).
The Neuro-Symbolic Concept Learner
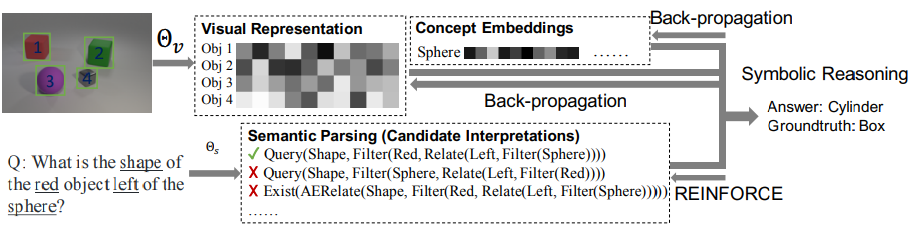
Figure: The Neuro-Symbolic Concept Learner aims to learn jointly a vocabulary of visual concepts, semantic embedding of question sentences, and how to execute them.
Architecture Overview
The model is rather involved and complex, and can be summarized as follows:
-
Visual Perception module This module first detect objects in the scene, and then extracts features (
ResNet-34) from the relevant regions usingRoI-pooling. They make use of a pretrainedMask R-CNNto generate the object proposals. In the end, each obejct is represented with the concatenation of its region-based feature (self) and global image features (context) -
Concept Quantization: Each object representation is then mapped to an attribute-specific embedding space (e.g. shape attribute). The actual attribute value for the object are obtained by comparing (cosine distance) the embedding to concept vectors for each attribute, also learned by the model. The same process is used to represent relational concept (e.g., left), except with the concatenation of two objects representations.
-
Semantic parser: The question in natural language are transformed into an executable program , formulated in the
DSLlanguage. The basic blocks of the language include basic fundamental operations such as filtering objects with a specific concept value, querying the attribute of an object etc. Additionally, the module makes use of recurrent architecture (bi-directionalGRUhere). TheDSLbuilding blocks are implemented in a differentiable manner, in particular making use of soft-attention
Training
Additionally, the model is trained using curriculum learning:
- First, learn basic attributes from simple questions: what’s the color ?, what’s the shape ? etc
- Learn referential expressions and basic relational concept: how many objects are on the right of the red object ?
- Tackle all remaining more complex questions
The training is done end-to-end, where the training objective consists in maximizing the right answer after executing the program (parsed question) on the visual representations (outputs of the perception modules and concept quantization).
Experiments
The model performs as well as existing baselines. More importantly, they also perform generalization experiments:
-
Generalization to new compositions. Test and train sets contain opposite (color, shape) combinations but the experiments lack details. For instance, their solution is based on seeing attributes as operators using pretrained frozen attribute operators to avoid overfitting, but it is not clear what they are pretrained on.
-
Generalizing to new visual concepts. Test with image that contains a color that has never been seen during training. The proposed solution is to fine-tune the model on a few images of the held-out split.
-
Generalizing to new scenes. For instance tackle questions or scenes that have a larger number of objects, or longer questions, or more referential levels. The model seems to scale fairly well.
-
Transfer to other tasks . Use the visual concept learned to measure performance on image caption retrieval (i.e. retrieve images based on simple captions like “there is a yellow cube”).